The Agentic Development Protocol
An open standard for shipping production software with AI agent teams — verified, not trusted.

The teams failing with AI aren't using worse models. They're running the same methodology with faster typists.
Parallel agent sessions collide. State gets lost between runs. Senior engineers spend their days reverse-engineering what the AI actually did. Velocity goes up; trust goes down — and nobody can prove the system still works tomorrow. ADP is the methodology layer that closes that gap.

Five patterns. One standard.
Stable roles, dynamic dispatch
Fixed agent roles with a clear contract; work is dispatched dynamically against them. The org chart is the constant, not the agent.
PDCA with evidence-based Check
Plan-Do-Check-Act, where Check is not a vibe. Every claim carries a receipt; the gate ACCEPTs or it doesn't.
The process-miss ledger
Every miss becomes a rule. Failures aren't postmortems you forget — they're committed to the ledger and become the standard the next run is held to. A depth-ratchet.
Token economics & deploy ladder
Cost is measured in tokens, not mandays. Work climbs a deploy ladder with a target cadence band, so spend maps to shipped, verified change.
Build to Rebuild
Docs and tests are the asset; code is a build artifact. If you can regenerate any module from its docs and tests, you own the system — not the AI that wrote it.
Get protocol updates
New versions, benchmark results, and audit findings as they ship. No marketing noise.
The protocol is free. The judgment isn't.
Senior AI consulting — architecture, governance, and agentic delivery. Productized, fixed-scope engagements; you're buying calibration, baselines, and accountability, not hours.
AI & Agentic Diagnostic
I map your AI-coding and agentic workflow against the failure modes I've already hit in production — including regeneration-readiness: can your team rebuild any module from docs and tests alone? You leave with a written diagnostic and an honest go/no-go.
Build & Install
Design and install governed agentic-AI systems — multi-agent orchestration, scoped RAG, LLM threat modeling — plus the ADP process layer that keeps parallel AI sessions safe. I train your team to autonomy on the way out.
Fractional Lead AI / Architect
Your senior AI architect across initiatives: weekly direction, evidence-based review on closed work, and the methodology shift embedded — mandays→tokens, governance that sticks. Your team scales without you scaling.
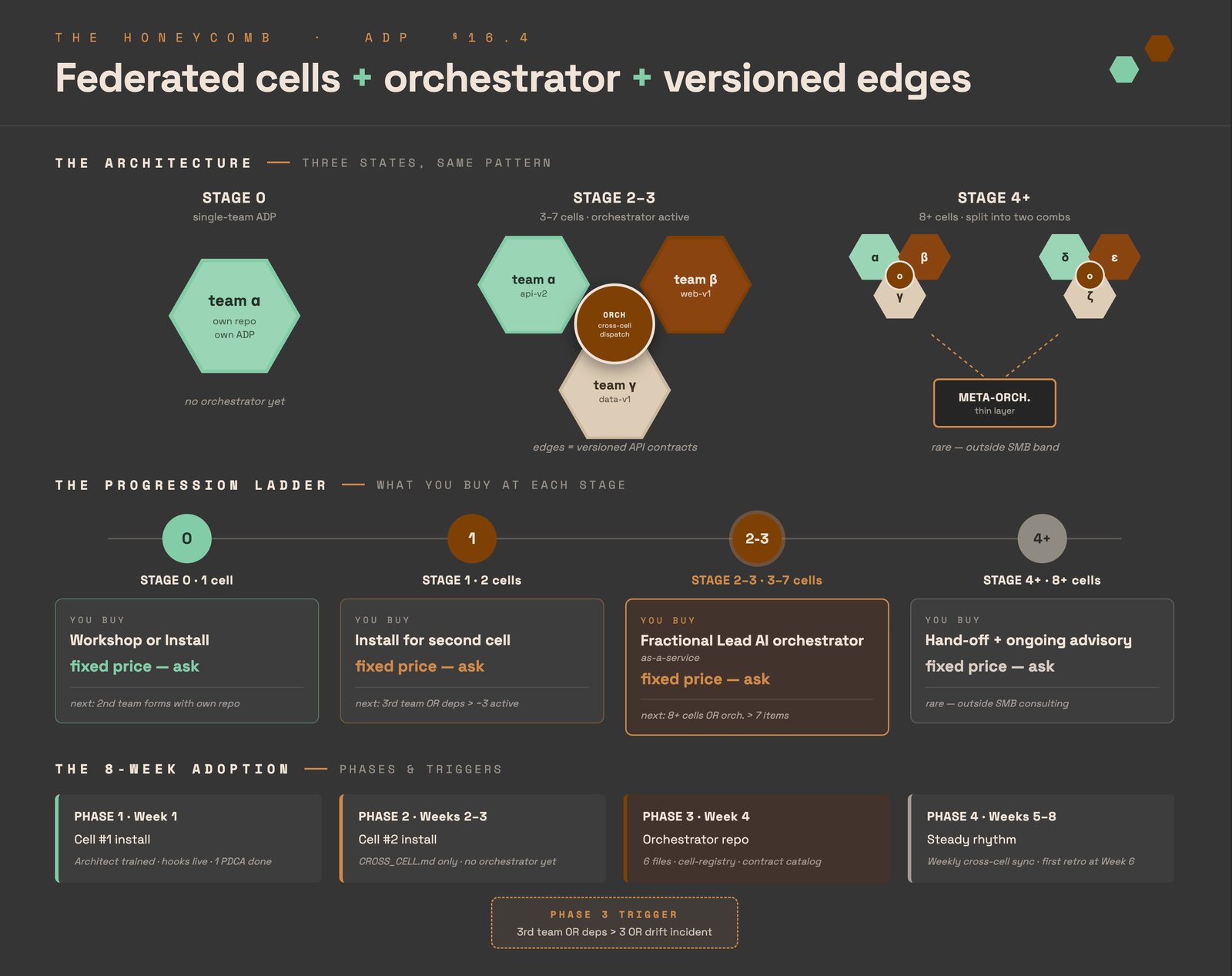
From one cell to a federated org.
One team or many: the same protocol scales into federated cells with an orchestrator and versioned edges between them. This is the published design for multi-team adoption — a roadmap, not yet production-proven (n=0). We label it honestly.

Why ADP, the receipts, and the methodology shift — in 12 pages.
For CTOs, Heads of Engineering, and senior PMs. Subscribe with your work email to get the briefing — plus new versions and benchmark findings as they ship.
Every claim has a receipt.
So do the weaknesses.

Guillermo Blanco — 25 years of program leadership, now building in production with AI agents.
Senior AI consultant — PMP since 2007 and Google Cloud Generative AI Leader certified — with a track record leading delivery across banking, insurance, and SaaS in Europe and Latin America. ADP isn't a theory deck — it's the methodology extracted from running an AI agent team in production, falsifications and all. The receipts above are his git history.
Connect on LinkedIn →